Moving to the cloud — The database, the images, and the wardrobe


Juan Speziale
Director, Engineering


In the not so distant past, before the advent of object storage services like Amazon S3 (2006) and Google Cloud Storage (2008), engineers like me often found it easier to leverage high-powered relational databases to store images along with the rest of the data. It was a cheap and easy solution.
The relational database approach, while offering many advantages, didn’t come without issues. Probably the biggest one was the size of the database — it grows really fast, and simple tasks like backups or making a copy become a nightmare. Data migration and re-platforming are other issues often faced.
That’s where our story begins. Recently, we had a client request to move out of an onsite data center to the Cloud for both performance improvements and cost savings.
Our first task was deciding how to do it: we could take a snapshot of the database and restore it in the Cloud, but would we just be bringing our existing problems to the Cloud? If we transferred our technical debt to this new infrastructure, would we be doing ourselves a favor?
We decided that this was the right time and a great opportunity to move the images out of the database and get rid of all the underlying related issues. We would be able to reduce the database blueprint — lowering ongoing costs — by leveraging a much smaller and cheaper instance. Last but not least, we would be able to make better use of the available services in the new infrastructure.
For many reasons — in order for the client to buy in — we had to be efficient and not slow the overall migration down. The cost savings and optimizations were really good — but there were larger business considerations we were battling, too.
We were not satisfied with this being the only major improvement moving to the Cloud. We also decided to move to refactor and migrate another engine to reduce license costs and take more advantage of the Cloud, in this case, AWS. But that deserves its own post.
Extraction and migration — the easy part
The first step was to extract the images and store them in an encrypted S3 bucket, leaving a reference to the new key in exchange for the binary data.
One option from AWS is AWS Snowball. Think of it as an external hard drive on steroids in which you locally host the device, load your data, ship it back to Amazon, and then they connect it to the AWS network and you can restore the data into an S3 bucket. We requested the device from AWS and after getting it up and running — after a few tests — we found out that the throughput was not good enough. It worked well with big objects, but in our case, we had millions of small ones. AWS recommended batching small files together to improve the performance, but either way, it was taking too long.
Without wasting more time, we decided to optimize the connection with AWS and send the files over the internet.
Applications changes — the not-so-easy part
Now that we had a good way to move the images to S3, we had to think about how the application was going to consume and store the images.
We decided to create an API as a gateway to encapsulate all the logic around images instead of allowing the different client applications to access different sources directly. This way, we can handle each request and get or save the images from/into the right place, and all this logic would be transparent from the client application.
Normally something like this could be done by updating the app to use the API instead of the database. In this particular case, the application is deployed to a preview environment before going to prod and being fully available. Both environments are using the same database, so each new version must be backward compatible with the previous one, without exception.
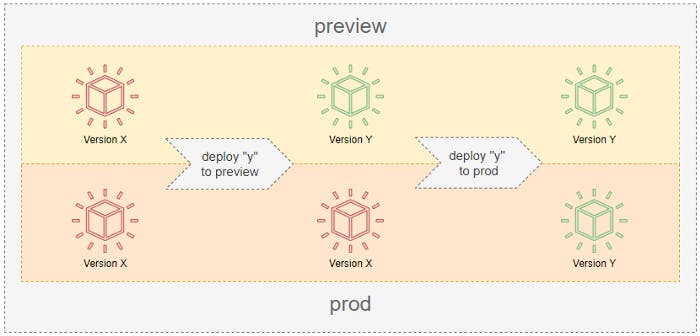
Taking that into consideration we divided this into 3 phases:
Phase 1 — Get Ready
Phase 2 — Hybrid
Phase 3 — Jump
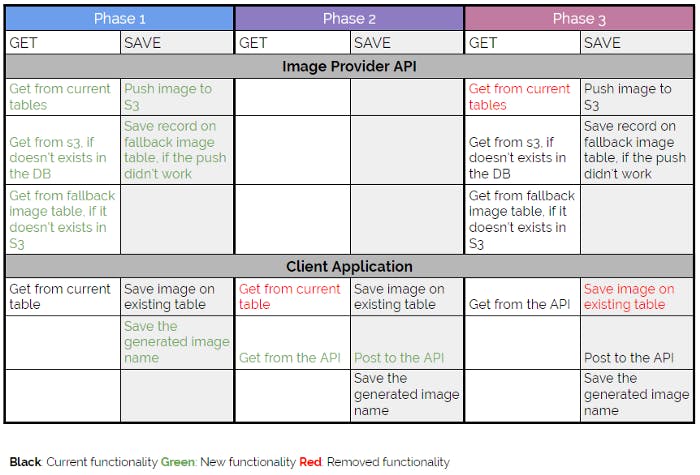
Phase 1 — Get Ready We built the API to manage the images and named it “Image Provider.” We also did all the modifications to the database and the app to start saving a name in combination with the actual image.
The API had a fallback mechanism to store the images locally, in case S3 was not available or something went wrong at the moment of pushing the image. The GET was a cascade operation to make sure we covered all the different places where the image could be stored.
After this version was deployed to both environments and the app was always saving an image name, we did the extraction and the upload to S3.
Phase 2 — Hybrid This was the real first step to move away from the database as a source of images. This version of the app started using the API to get the images instead of using the DB, but in order to keep backward compatibility, the image was saved in both places, the API and the DB. Remember that at some point in Preview we were going to have this version, but in Prod, the app was still looking for images in the database (middle state of the deployment).
After this version was deployed to both environments and the app was using the API to get and save images, we moved the delta of images that were not migrated previously.
Phase 3 — Jump This was the most difficult deployment that we did. If something went wrong with the API and the images were not managed correctly, we couldn’t come back. Previously, if something was wrong, the images were also saved in the DB, but in this version, we removed that step. We had to guarantee that the API worked correctly and the images were in S3 or the fallback table, otherwise, we would have had a huge problem.
Conclusion: Takeaways for you (and us)
The project was a success. The migration was completed on time, we were able to make improvements, and we saved costs for the client in exchange for a short amount of extra work. Our thinking and planning paid off.
You may think that this project was unique, and specific combinations of different variables made a simple task a little bit more complicated than usual. What makes this experience worthy to share, is to show that you should always think above and beyond. Try to find those opportunities to make things better and not just accept things as they are. Last but not least, we have a few takeaways that may be useful for you as well:
- The creation of a layer in front of S3, the API, was a good decision because it allowed us to incorporate different behaviors that were transparent for the client application.
- On every put to S3, we calculate the md5 of the image, that way we can make sure the saved object is not corrupted.
- The fallback mechanism was a good solution to allow the client application to continue working as usual if the connection with AWS or S3 was not available. We sync the content of that table as soon as the problem is solved.
- We included a bunch of logs and metrics around the API in order to make sure and guarantee it was working correctly before deploying Phase 3.
- Do not store images into the relational database. Today there are other, better places.
Stay tuned to learn more about Cloud computing from the Modus team.


